Native RL APIs in vLLM
As post-training workloads continue to scale, we’ve seen widespread adoption of vLLM as the inference engine of choice. However, two issues repeatedly arise:
- Weight syncing between training and inference is implemented in an ad-hoc fashion and duplicated across frameworks.
- Asynchronous RL setups become fragile at scale, especially in P/D and DPEP deployments.
In this post, we introduce two improvements in vLLM:
- Native weight syncing APIs that provide a standard interface for RL frameworks.
- Improved support for asynchronous RL, including a new pause mode and fixes for deadlocks in DPEP setups.
Native Weight Syncing APIs in vLLM
Background
In online RL setups, vLLM model weights must be synced periodically to make sure that the rollouts generated are from the latest or a recent version of the model weights, so as to provide more useful feedback.
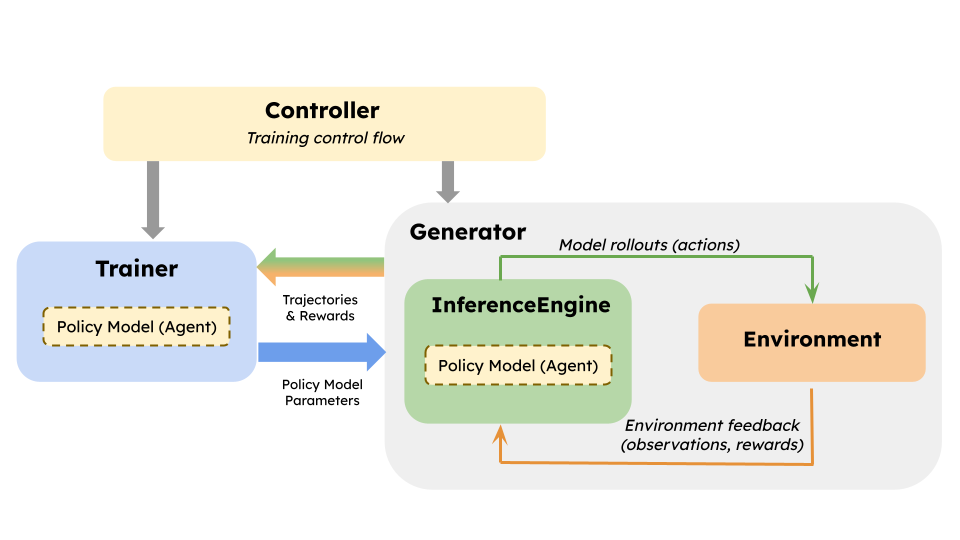
Figure 1: RL system overview.
Traditionally, this weight loading has been handled by each RL framework separately, typically by extending vLLM workers with custom logic for receiving and loading weights. While this works, it leads to a few issues:
- Added complexity: Framework authors have to implement and maintain custom worker extensions, and it would be better to have native support for popular transport strategies.
- Duplicated effort: Most RL frameworks end up having very similar implementations (e.g., packed tensor transfer, RPC endpoints).
- Version locking: Frameworks typically have ad-hoc ways of dealing with pre/post-processing of received weights to enable vLLM workers to load them, which can lead to version locked implementations.
New APIs in vLLM
We introduce native weight syncing APIs in vLLM to standardize this. The weight transfer APIs consist of four phases with a pluggable backend:
- Initialization (
init_weight_transfer_engine): Establishes the communication channel between the trainer and inference workers. Called once before the training loop begins. - Start weight update (
start_weight_update): Start a weight update. Called after each training step (or batch of steps). Prepares the vLLM workers to receive weights. - Update weights (
update_weights): Update all or a subset of weights from the trainer to the inference engine. Can be invoked multiple times for chunked weight transfers. - Finish weight update (
finish_weight_update): Finish the current weight update. Runs any necessary post-processing (e.g., quantization).
Corresponding APIs are implemented at the API server and the engine level.
Currently, we support the following backends:
- NCCL: Uses NCCL broadcast operations for weight transfer between training and inference workers on separate GPUs.
- IPC: Uses CUDA IPC for same-device weight transfer via shared memory handles.
Both backends support an optimized packed implementation to minimize serialization overhead.
The core transport logic is implemented with a pluggable WeightTransferEngine abstraction to separate weight transport from the worker implementation, allowing users to easily bring in their own implementations. The core idea is that initialization and update weights phases are typically customized by RL framework developers and include transport logic, while start and finish are control messages, and involve transport-agnostic pre/postprocessing in vLLM.
Note
The HTTP weight transfer endpoints require VLLM_SERVER_DEV_MODE=1 to be set.
Example
For example, here is how the different operations would look for weight transfer via NCCL with FP8 quantization on vLLM:
![]()
Figure 2: Weight transfer via NCCL with FP8 quantization on vLLM.
The new APIs can be used as follows:
1. Configure the engine for weight transfer
from vllm import LLM
from vllm.config import WeightTransferConfig
llm = LLM(
model="my-model",
weight_transfer_config=WeightTransferConfig(backend="nccl"),
)
2. Initialize communication state: Initialize communication state between trainer and inference engine. The trainer’s rank 0 process and all inference workers join a shared NCCL process group.
from vllm.distributed.weight_transfer.base import WeightTransferInitRequest
# Initialization for inference
llm.init_weight_transfer_engine(
WeightTransferInitRequest( # <--- initialization parameters
init_info=dict(
master_address=master_address,
master_port=master_port,
rank_offset=1, # <--- offset accounts for trainer rank 0
world_size=world_size, # <--- trainer + all inference workers
)
)
)
# Initialization for training
from vllm.distributed.weight_transfer.nccl_engine import (
NCCLWeightTransferEngine,
)
group = NCCLWeightTransferEngine.trainer_init(
dict(
master_address=master_address,
master_port=master_port,
world_size=world_size,
)
)
3. Send weights from the trainer: Start the weight transfer on the trainer. WeightTransferEngine implements a trainer_send_weights method that takes in an iterable list of parameters and initializes the transfer for all or a subset of parameters. Users can also implement their own send functionality. Here, we can also leverage packed tensor broadcasting for higher throughput transfer by batching multiple small tensors into a larger buffer.
from vllm.distributed.weight_transfer.nccl_engine import (
NCCLTrainerSendWeightsArgs,
NCCLWeightTransferEngine,
)
trainer_args = NCCLTrainerSendWeightsArgs(
group=group,
packed=True, # use packed broadcasting for efficiency
)
# send weights from an `AutoModelForCausalLM` instance
NCCLWeightTransferEngine.trainer_send_weights(
iterator=model.named_parameters(),
trainer_args=trainer_args,
)
4. Receive weights in the inference engine
from vllm.distributed.weight_transfer.base import WeightTransferUpdateRequest
# executed asynchronously while trainer sends weights
llm.start_weight_update()
llm.update_weights(
WeightTransferUpdateRequest(
update_info=dict(
names=names,
dtype_names=dtype_names,
shapes=shapes,
packed=True,
)
)
)
llm.finish_weight_update()
Customizing Weight Transfer
One of the primary goals for the weight transfer APIs is to enable RL frameworks to implement custom weight transfer strategies with vLLM. With the new APIs, users would implement and register a custom WeightTransferEngine:
from dataclasses import dataclass
from typing import Iterator, Callable, Any
from torch import Tensor
from vllm.distributed.weight_transfer.base import (
WeightTransferEngine,
WeightTransferInitInfo,
WeightTransferUpdateInfo,
)
# define custom dataclasses for initialization and update weights metadata
@dataclass
class MyInitInfo(WeightTransferInitInfo):
"""Custom initialization info."""
...
@dataclass
class MyUpdateInfo(WeightTransferUpdateInfo):
"""Custom update info."""
...
# custom weight transfer engine
class MyWeightTransferEngine(WeightTransferEngine):
init_info_cls = MyInitInfo
update_info_cls = MyUpdateInfo
def init_transfer_engine(self, init_info: MyInitInfo):
...
def receive_weights(
self,
update_info: MyUpdateInfo,
load_weights: Callable[[list[tuple[str, Tensor]]], None],
):
...
@classmethod
def trainer_send_weights(
cls,
iterator: Iterator[tuple[str, Tensor]],
trainer_args: dict[str, Any] | Any,
):
...
# finally, register the weight transfer engine
from vllm.distributed.weight_transfer import WeightTransferEngineFactory
WeightTransferEngineFactory.register_engine("my_weight_transfer", MyWeightTransferEngine)
Note that the trainer_send_weights method is optional to use. It encodes send logic used on the trainer and users are not required to structure their send logic in this way.
The above simple API can enable many advanced use-cases. As a prototype, we demonstrate how sharded weight transfer in the style of Etha can be implemented here.
Improved Pause/Resume Support for Asynchronous RL
In asynchronous RL, weights are updated while inference requests are still in flight. Typically, weight syncing involves three operations in async RL: pausing generation, transferring updated weights, and then resuming generation. Users choose how to deal with in-flight requests (e.g., abort all running requests, or resume generation from previously generated tokens), as well as keeping or discarding the KV cache.

Figure 3: Asynchronous RL system diagram, inspired by AReaL. Training and generation overlap, with training utilizing 4 samples for each step. After a training step finishes, all the engines are paused, weights are updated, the KV cache is discarded, and then the engines are resumed. KV cache is recomputed on resumption and generation progresses as before.
Keep Mode for Pause/Resume
To safely update weights while the inference engine is running, vLLM provides pause_generation and resume_generation methods. The same functionality is available in the HTTP servers as POST /pause and POST /resume APIs. Previously, AsyncLLMEngine.pause_generation supported two modes:
- abort all requests
- wait for requests to finish
We add a third option: keep mode. The different modes are compared in the table below:
| Mode | Explanation | Client-side impact | Asynchronous RL possible? |
|---|---|---|---|
abort |
Aborts all ongoing requests | Client must handle retries | Yes |
wait |
Wait for all ongoing requests | Client need not retry | No, generation needs to finish before weight update |
keep |
Pause ongoing requests | Client need not retry | Yes |
Keep mode can be used as follows:
# pause - preserve ongoing requests
await engine.pause_generation(mode="keep")
# update weights here
# resume
await engine.resume_generation()
In keep mode:
- Ongoing requests are paused but not discarded.
- The scheduler is stopped, but state is preserved.
Fixing Deadlocks in DPEP Setups
Large scale asynchronous RL requires careful coordination for in-flight weight updates in DPEP deployments. In vLLM, a DPCoordinator ensures that generation is carefully coordinated across vLLM ranks to prevent deadlocks. More specifically, each DP rank executes a forward pass while there are active requests scheduled in any of the DP ranks.

Figure 4: DP-coordinated generation across vLLM ranks.
Previously, asynchronous RL in DP deployments with vLLM often led to deadlocks, primarily because some engines would have received a pause signal while others would be actively handling requests and waiting for all engines to join. One of the reasons this occurred was because the pause state was tracked in the AsyncLLM object, while DP coordination messages were exchanged between EngineCore processes and the DPCoordinator. To illustrate, for a DP world size of 2, one could have a deadlock scenario as follows:
- API Server DP Rank 0 receives a generation request and forwards it to
EngineCore. API Server issues aFIRST_REQmessage to theDPCoordinatorto start a new wave. The request is forwarded to DP Rank 0EngineCorewhich begins a new scheduler step. - The Controller issues a
/pauserequest to both the engines. Pause state is set in theAsyncLLMobject, and new requests are not forwarded toEngineCore. API servers on all DP ranks return right after. - The Trainer issues weight update requests. Meanwhile, DP Rank 0
EngineCorehas entered the forward pass and is waiting for other DP ranks to join. (For simplicity, we ignore thestart_weight_updateandfinish_weight_updaterequests here). - The weight update request reaches DP Rank 1
EngineCoreand the replica enters an NCCL broadcast collective waiting for other ranks. The weight update request is queued on DP Rank 0EngineCore. DPCoordinatorsends aSTART_DP_WAVEmessage to DP Rank 1EngineCorebut the message is queued.- Different ranks are in different collectives and deadlock.
The same scenario is represented here:

Figure 5: A deadlock scenario possible in DPEP deployments in vLLM.
We address this with two changes:
1. Move pause logic into EngineCore. Instead of tracking pause state at the AsyncLLM entrypoint layer, it is now handled directly in the scheduler. This reduces race conditions between pause and generation requests.
2. Two-phase pause/resume.
- Phase 1 (local pause): Each engine pauses scheduling but continues stepping by respecting any inbound
START_DP_WAVErequests, so it can still participate in required forward passes. - Phase 2 (global pause): Currently, all the ranks perform a global all-reduce every 32 steps to check if there are pending requests in any DP rank. In the same all-reduce phase, we also check if all the engines are in the “local pause” state. If all the ranks agree, they stop together.
This ensures:
- No rank gets stuck waiting.
START_DP_WAVEis respected even if an engine receives a pause request.- All workers transition consistently.
Thus, the same scenario as before is handled gracefully:
- API Server DP Rank 0 receives a generation request and forwards it to
EngineCore. API server issues aFIRST_REQmessage to theDPCoordinatorto start a new wave. The request is forwarded to DP Rank 0EngineCorewhich begins a new scheduler step. - The Controller issues a
/pauserequest to both the engines. The pause request is forwarded toEngineCorefor both the ranks. The pause request is queued in DP Rank 0EngineCoreuntil the step is complete. Note that the API server doesn’t yet return. - DP Rank 0
EngineCorestarts executing a forward pass, with workers waiting on an all-to-all collective. - DP Rank 1
EngineCorereceives the pause request, enters “local pause” state. DPCoordinatorsends aSTART_DP_WAVEmessage to DP Rank 1EngineCore.- DP Rank 1
EngineCorestarts executing a forward pass. Forward pass completes since both DP ranks joined. - DP Rank 0
EngineCoreprocesses the pause request, enters “local pause” state. - DP Rank 0 and DP Rank 1
EngineCoreparticipate in a periodic all-reduce, realize both engines are in “local pause” state, and enter “global pause” state. - API servers return on the
/pausecall. - Trainer issues weight update requests. API servers forward the weight update request to the
EngineCoreprocesses. (For simplicity, we ignore thestart_weight_updateandfinish_weight_updaterequests here). - All vLLM workers enter the NCCL broadcast collective. Trainer starts NCCL broadcast.
- Weight update finishes successfully.

Figure 6: Deadlock-free pause/resume in DPEP deployments with the two-phase protocol.
Validation
Demonstrating the New RL APIs
We demonstrate usage of the new RL APIs in SkyRL.
In SkyRL, the trainer interacts with inference engines over HTTP. For weight syncing, SkyRL uses the native weight syncing APIs, as well as the native /pause and /resume APIs for asynchronous RL. The integration with the native RL APIs is detailed in the docs, and we demonstrate asynchronous training for Qwen3-1.7B on the original DAPO recipe (example).

Figure 7: Asynchronous training of Qwen3-1.7B on the DAPO recipe in SkyRL using the native RL APIs.
Validation at Scale: Fully Async RL in a Wide-EP Setup
The Prime-RL team has validated the RL APIs against a deployment of zai-org/GLM-5.1-FP8 with inference running in a P/D disaggregated setup across 16 8xH200 nodes — 2 replicas of 4P+4D both with DPEP32 for both prefill and decode. All instances were also configured with CPU KV cache offloading with a capacity of 1TB per node. The routing across engines was enabled using vllm-router which provides cache-aware sticky routing. The Trainer ran a BF16 model equivalent (zai-org/GLM-5.1) on another 16 8xH200 nodes, on a custom math environment with IcePop as the algorithm of choice. This deployment has proven stable over 100+ steps while training, with growing evaluation performance, an upward RL curve, stable KL mismatch and weight updates progressing normally.

Figure 8: Prime-RL validation of fully async RL with zai-org/GLM-5.1-FP8 across 16 8xH200 nodes.
Conclusion
We’ve seen growing interest in the vLLM RL community for building on top of the new RL APIs. Some ongoing work from the vLLM RL community includes integrating a new K8s-native weight transfer engine as well as supporting sharding-aware, RDMA-native weight transfer in a generic way. New development is tracked in the vLLM RL Roadmap.
Read more about the RL tooling in vLLM in the docs:
Try out the new APIs on vLLM here: https://github.com/vllm-project/vllm/tree/main/examples/rl.
Acknowledgements
Thanks to the following groups and individuals who made this possible:
- Prime-RL team (especially Matej Sirovatka) and Junjie Zhang for helping to validate and debug the RL APIs with large-scale runs.
- NemoRL team for providing an optimized packed tensor implementation.
- Robert Shaw for organizing RL-related efforts.
- Kyle Sayers for making quantized weight reloading possible through layerwise reloading.