Accelerating vLLM-Omni Inference with AutoRound Quantization
TL;DR
We are excited to announce that AutoRound — Intel’s state-of-the-art post-training quantization (PTQ) algorithm — is now fully integrated into vLLM-Omni, enabling a streamlined quantize-once, serve-directly workflow. This collaboration brings W4A16 (4-bit weight / 16-bit activation) quantization to multimodal Omni, diffusion video, and multi-stage image generation pipelines.
Key empirical highlights from our production-grade benchmark suite include:
- Massive VRAM Savings: Up to 62% total checkpoint size reduction for large Omni models, cutting Qwen3-Omni-30B-A3B from 66 GB down to 25 GB.
- Accuracy Preservation: The W4A16 quantized variant of Qwen3-Omni-30B achieved an impressive score on OmniBench, slightly better than its BF16 reference. Concurrently, it limits text-to-image quality drift to a mere ~1.3%, suggesting that 4-bit quantization can preserve multimodal quality under the evaluated workloads.
- Production Serving Wins: Unlocks advanced architectural optimization on Intel XPU (B60), achieving 1.55–1.67x faster guided generation via CFG Parallel execution compared to sequential BF16 baseline serving.
- Cross-Backend Integration: Native execution paths verified across Intel XPU and NVIDIA GPU architectures.
1. Introduction: vLLM-Omni Meets AutoRound
vLLM-Omni is designed for high-performance serving across diffusion models, multimodal Omni models, and related multi-stage generation stacks. That breadth makes quantization unusually valuable: the goal is not only to shrink a single transformer, but to make a diverse runtime portfolio easier to deploy on real hardware.
AutoRound, developed by Intel and described in the EMNLP 2024 work on weight rounding via signed gradient descent, is a tuning-based post-training quantization algorithm. Its core idea is to jointly optimize rounding and clipping with three learnable parameters per quantized tensor: V for rounding offset, plus alpha and beta for clipping range control. In practice, that gives AutoRound stronger low-bit accuracy than naive round-to-nearest baselines while still producing static checkpoints with zero extra inference-time quantization overhead.
This three-layer collaboration — algorithm work in AutoRound, runtime integration in vLLM-Omni, and a growing catalog of INT4 checkpoints on HuggingFace — tells a coherent story: AutoRound is not just a quantization technique, but an end-to-end path from research to production-ready low-bit omni inference.
The runtime path is intentionally simple. vLLM-Omni reads the checkpoint metadata, detects quantization_config.quant_method = "auto-round", remaps the checkpoint blocks to runtime modules, and selects the matching compute backend. This checkpoint-driven flow is especially important for production because it keeps the serving API identical to a normal model load.
2. Model Coverage
The validated AutoRound + vLLM-Omni ecosystem spans three primary multimodal paradigms.
2.1 Omni Multimodal Models
These models manage unified text, vision, and audio processing loops, presenting unique quantization challenges due to cross-modal embedding alignment.
- Qwen3-Omni-30B-A3B-Instruct (Intel/Qwen3-Omni-30B-A3B-Instruct-int4-AutoRound): Large-scale flagship multimodal model. Integrated and validated in vLLM-Omni.
- Qwen2.5-Omni-7B (Intel/Qwen2.5-Omni-7B-int4-AutoRound): Lightweight, low-latency cross-modal engine. Integrated and validated in vLLM-Omni.
2.2 Diffusion and Multi-Stage Image Generation
- GLM-Image (Intel/GLM-Image-int4-AutoRound): Multi-stage text-to-image pipeline. Integrated and validated in vLLM-Omni.
- FLUX.1-dev (vllm-project-org/FLUX.1-dev-AutoRound-w4a16): High-fidelity diffusion transformer (DiT). Integrated and validated in vLLM-Omni.
- BAGEL-7B-MoT (Intel/BAGEL-7B-MoT-int4-AutoRound): Checkpoint available; runtime integration in progress.
- Ovis-Image-7B (Intel/Ovis-Image-7B-int4-AutoRound): Checkpoint available; runtime integration in progress.
2.3 Video Diffusion
The Wan2.2 family represents state-of-the-art spatio-temporal video generation models with AutoRound INT4 checkpoints validated in vLLM-Omni:
- I2V-A14B (Intel/Wan2.2-I2V-A14B-Diffusers-int4-AutoRound)
- T2V-A14B (Intel/Wan2.2-T2V-A14B-Diffusers-int4-AutoRound)
- TI2V-5B (Intel/Wan2.2-TI2V-5B-Diffusers-int4-AutoRound)
3. Usage
By containing all quantization and tuning operations within the offline pipeline, the integration keeps production code streamlined and focused exclusively on high-performance inference.
3.1 Inference with a Quantized Model
For FLUX.1-dev, the Python API looks just like a normal vLLM-Omni load. The only difference is the checkpoint path.
from vllm_omni import Omni
from vllm_omni.inputs.data import OmniDiffusionSamplingParams
if __name__ == '__main__':
omni = Omni(model="vllm-project-org/FLUX.1-dev-AutoRound-w4a16")
outputs = omni.generate(
"A cat sitting on a windowsill",
OmniDiffusionSamplingParams(num_inference_steps=28, guidance_scale=3.5),
)
outputs[0].images[0].save("output.png")
For Wan2.2 video models, serving remains a standard vLLM-Omni command. Once the server is running, requests go through the same video endpoint used by the BF16 variant.
vllm serve Intel/Wan2.2-T2V-A14B-Diffusers-int4-AutoRound --omni --port 8091
curl -X POST "http://127.0.0.1:8091/v1/videos/sync" \
-F 'prompt=Cherry blossoms swaying gently in the breeze, cinematic motion' \
-F 'width=832' -F 'height=480' -F 'num_frames=48' \
-F 'num_inference_steps=40' -F 'guidance_scale=5.0' \
--output t2v_output.mp4
For Omni models such as Qwen2.5-Omni, the OpenAI-compatible chat interface also remains unchanged.
vllm serve Intel/Qwen2.5-Omni-7B-int4-AutoRound --omni --port 8091
curl -s http://localhost:8091/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Intel/Qwen2.5-Omni-7B-int4-AutoRound",
"messages": [{"role": "user", "content": "What is 2 + 3?"}],
"max_tokens": 128
}'
The important operational detail is that vLLM-Omni auto-detects the quantization metadata from the checkpoint. For pre-quantized AutoRound models, you do not need to add a separate --quantization flag during inference.
3.2 Quantizing a New Model
New checkpoints are generated offline with the AutoRound tool and then served directly by vLLM-Omni. No calibration or quantization work occurs during serving. This separation keeps quantization experimentation out of the hot serving path and ensures that production inference remains focused on execution efficiency.
# FLUX.1-dev
auto-round \
--model black-forest-labs/FLUX.1-dev \
--scheme W4A16 \
--batch_size 1 \
--disable_opt_rtn \
--dataset coco2014 \
--iters 0
# Wan2.2-T2V-A14B
auto-round \
--model_name Wan-AI/Wan2.2-T2V-A14B-Diffusers \
--format auto_round \
--scheme W4A16 \
--iters 100 \
--nsamples 32 \
--batch_size 1 \
--num-inference-steps 3 \
--guidance-scale 5.0 \
--dataset coco2014 \
--output_dir Wan2.2-T2V-A14B-Diffusers-int4-AutoRound
# Qwen3-Omni-30B-A3B-Instruct
auto-round \
--model Qwen/Qwen3-Omni-30B-A3B-Instruct \
--bits 4 \
--group_size 128 \
--format auto_round \
--iters 200 \
--lr 5e-3 \
--output_dir tmp_qwen3_omni_w4a16 \
--trust_remote_code
The resulting checkpoint includes quantization metadata in config.json:
{
"quantization_config": {
"quant_method": "auto-round",
"bits": 4,
"group_size": 128,
"sym": true,
"packing_format": "auto_round:auto_gptq"
}
}
In practice, the AutoRound and vLLM guidance suggests that 128 calibration samples and roughly 200 optimization iterations are often enough to reach stable convergence for many workloads, though larger or more sensitive models may benefit from more tuning. The exact calibration settings depend on model family, task type, and deployment constraints.
3.3 Quality Validation
For diffusion models, vLLM-Omni also provides a comparison tool for same-seed regression testing between a BF16 reference and a quantized candidate.
python -m vllm_omni.quantization.tools.compare_diffusion_trajectory_similarity \
--task t2i \
--reference-model black-forest-labs/FLUX.1-dev \
--candidate-model vllm-project-org/FLUX.1-dev-AutoRound-w4a16 \
--prompt "a cup of coffee on the table" \
--height 512 --width 512 \
--num-inference-steps 20 \
--seed 142 \
--output-json /tmp/flux_similarity/result.json
4. Quantitative Evaluation: Accuracy & Quality
Quantization is only useful if it preserves the model’s core intelligence. We subjected the AutoRound integration to extensive, multi-modality regression testing using automated evaluation suites.
4.1 Omni Multimodal Evaluation (OmniBench)
We used evalscope to run an identical evaluation across 100 highly complex multimodal tasks (incorporating both image and audio modalities simultaneously). The W4A16 model achieved a slightly higher aggregate OmniBench score than the BF16 baseline.
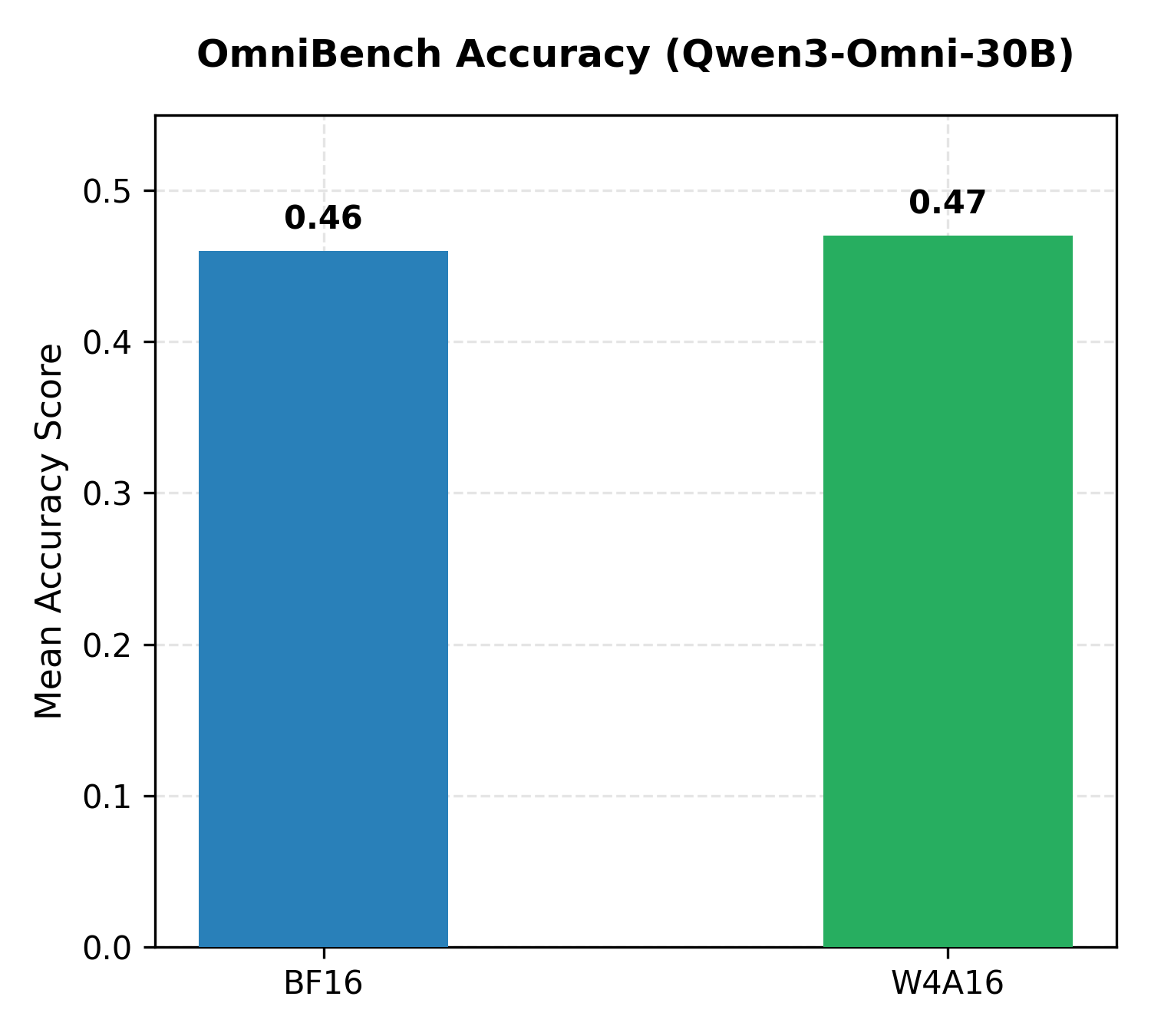
Figure 1: OmniBench results comparing BF16 and W4A16 AutoRound quantized variants of Qwen3-Omni-30B-A3B-Instruct.
4.2 Multi-Stage Diffusion Evaluation (TIIF-Bench)
For multi-stage text-to-image systems, performance was quantified across 9 structural sub-attributes evaluating alignment, composition, and fidelity.
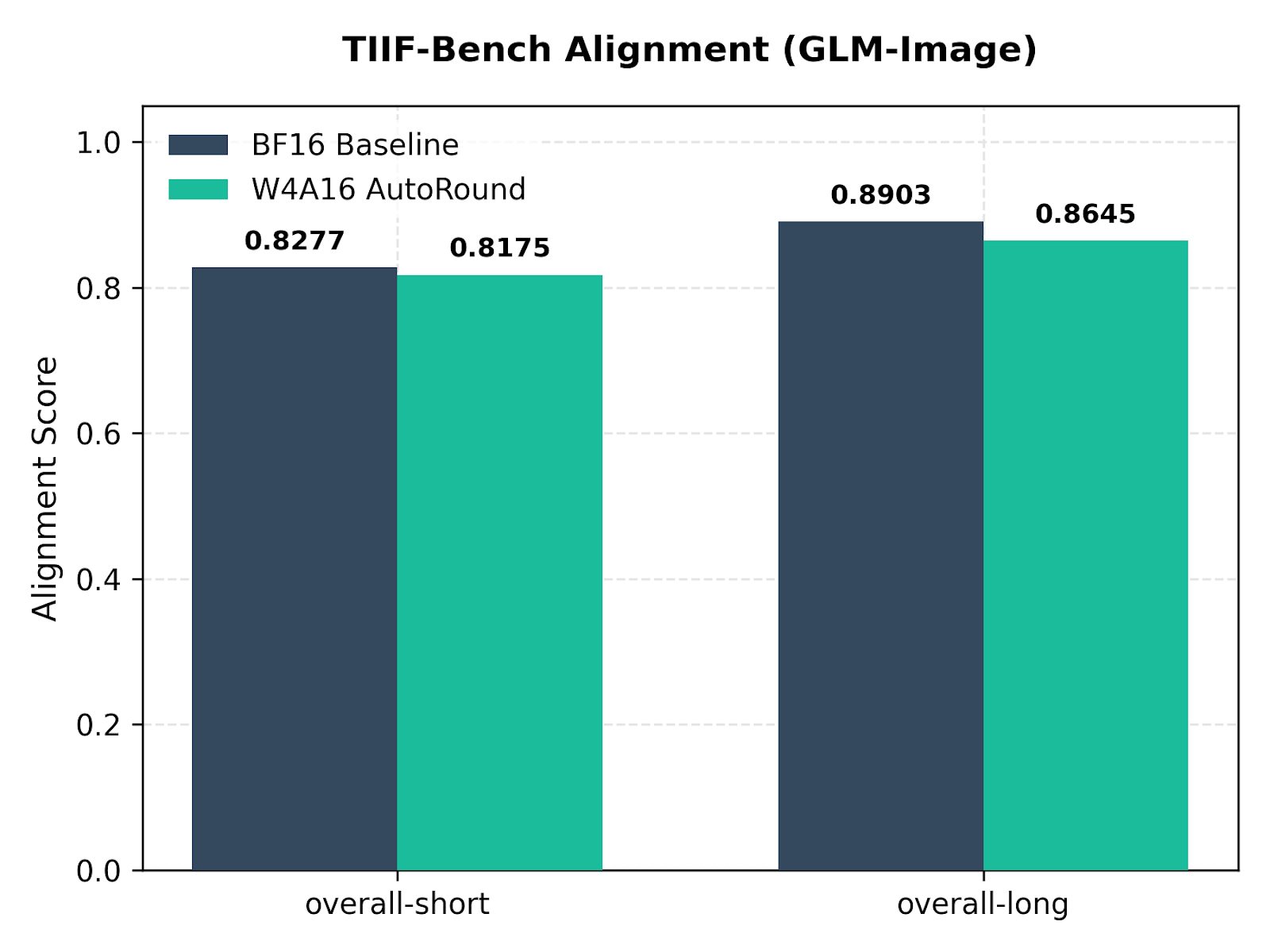
Figure 2: TIIF-Bench evaluation across 9 structural sub-attributes for multi-stage text-to-image pipelines.
The average accuracy degradation across all axes is ~1.3%, safely within acceptable tolerances for production deployments.
4.3 Video Generation Evaluation (Wan2.2)
Video pipelines are fragile under naive scalar quantization due to temporal consistency drift. AutoRound was evaluated using objective metrics across multiple dimensions:
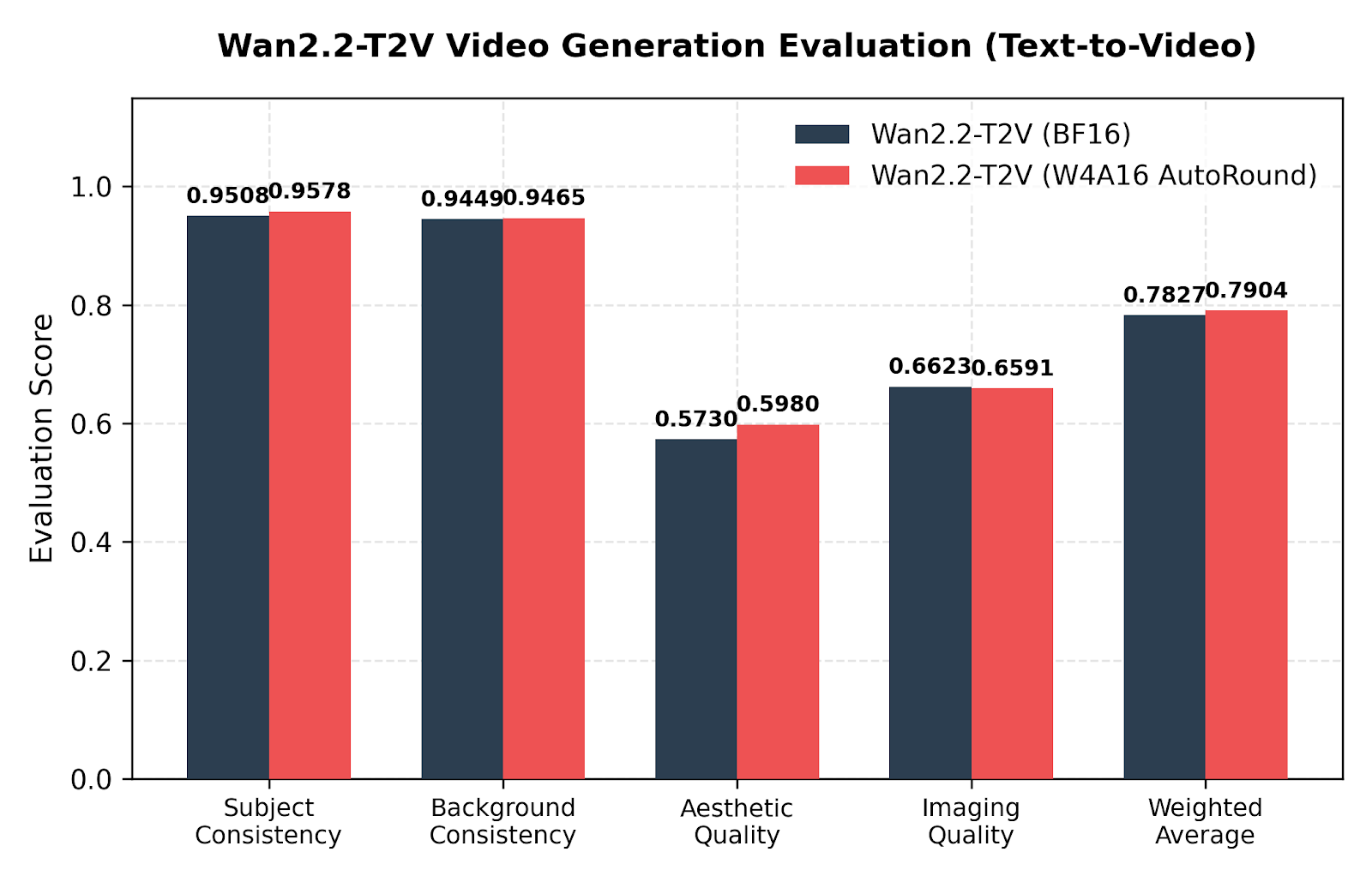
Figure 3: Text-to-Video evaluation on Wan2.2 T2V-A14B under W4A16 AutoRound quantization.
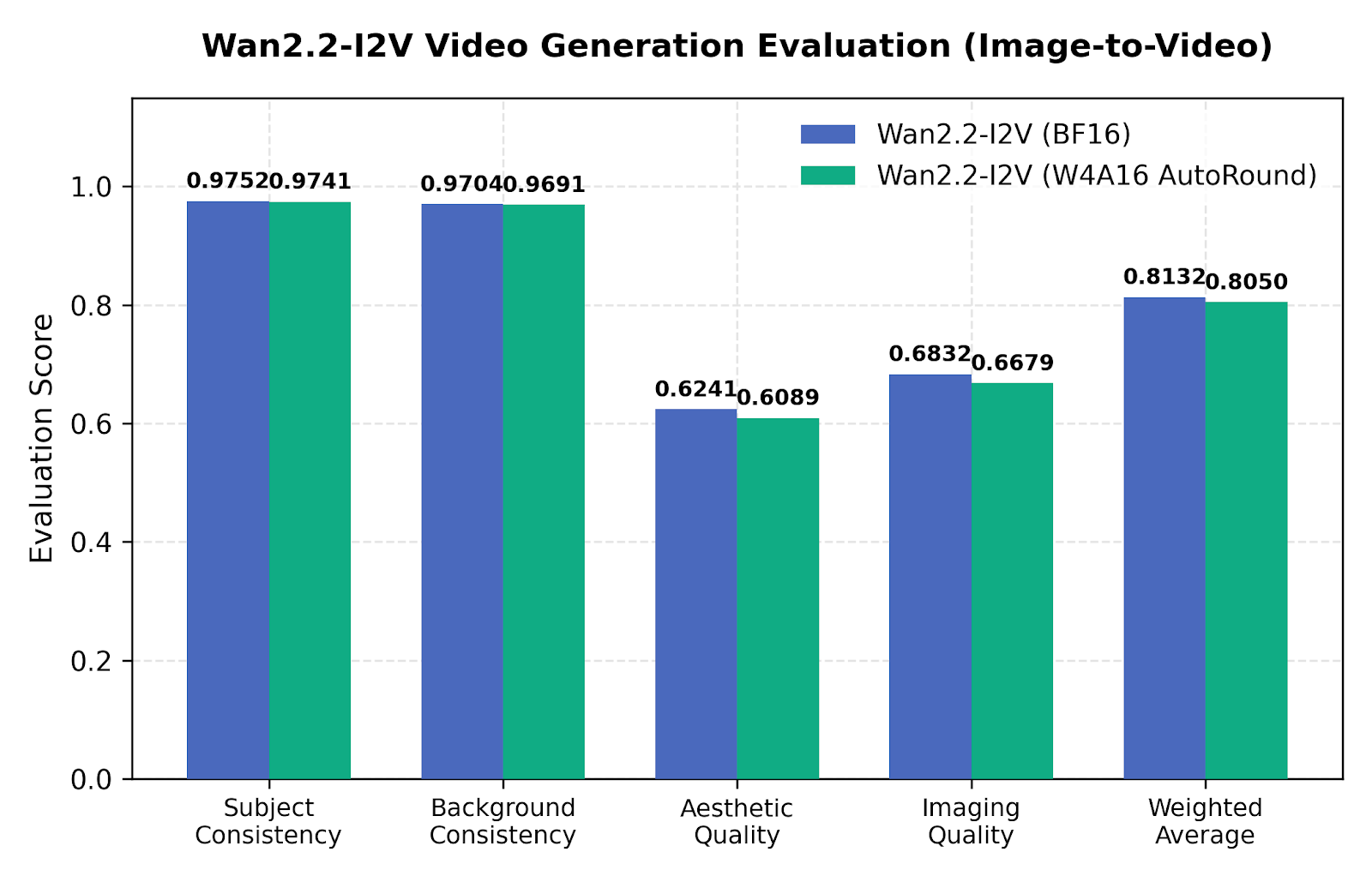
Figure 4: Image-to-Video evaluation on Wan2.2 I2V-A14B under W4A16 AutoRound quantization.
Under W4A16 AutoRound, the Text-to-Video variant (T2V-A14B) actually showed marginal improvements in structural consistency metrics. This behavior is consistent with the hypothesis that clipping optimization may provide a regularization effect.
5. Performance, Footprint, and Serving Benchmarks
5.1 VRAM Footprint Optimization
The first-order benefit of W4A16 AutoRound is a dramatic reduction in checkpoint size and execution memory footprint. W4A16 shrinks quantized weight storage from a BF16 baseline to roughly one quarter of the original weight footprint, which is why the first-order win is memory headroom. End-to-end speedups then depend on how much of the workload was previously bottlenecked by memory capacity or memory bandwidth.
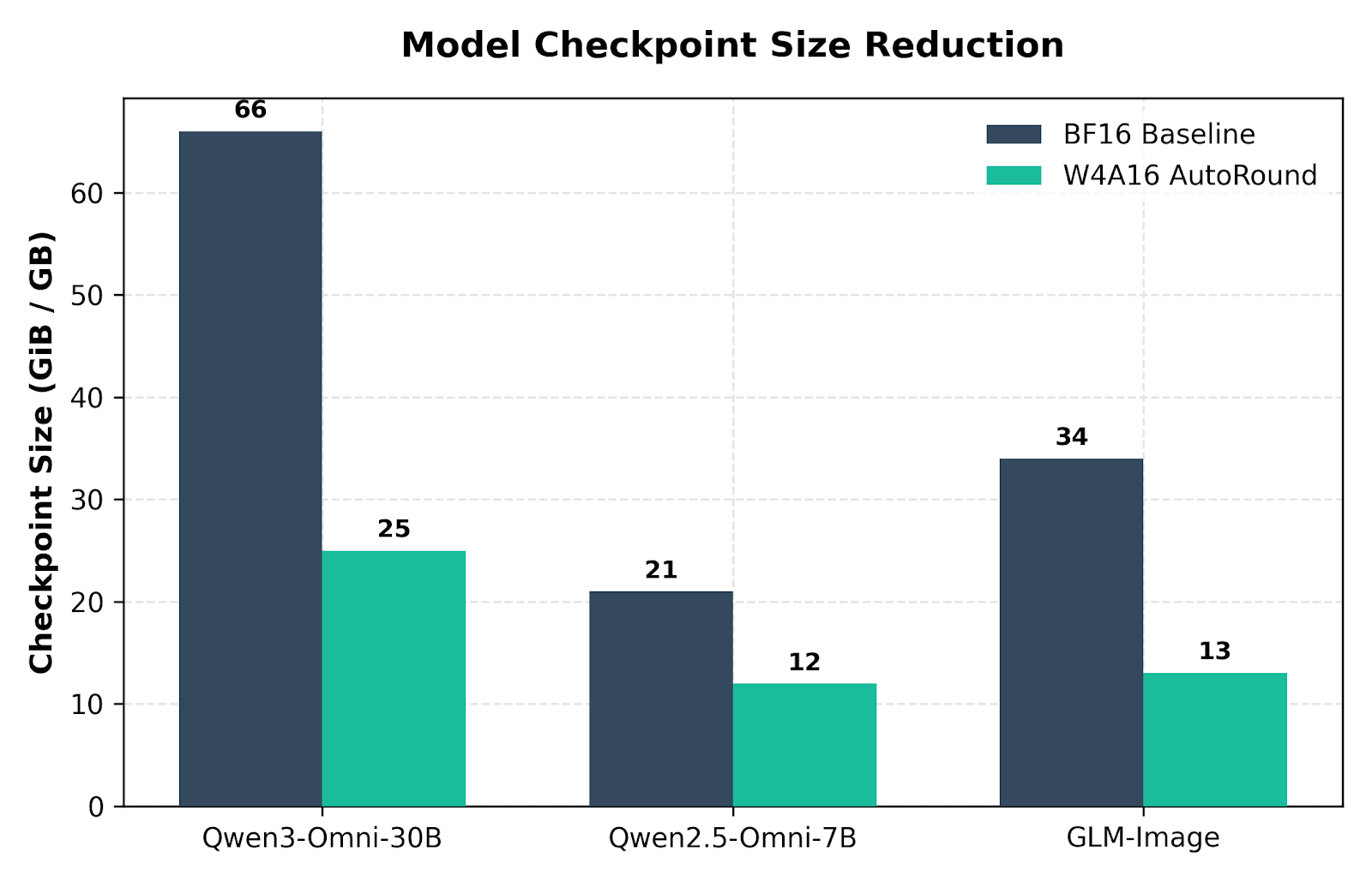
Figure 5: VRAM footprint comparison between BF16 and W4A16 AutoRound across vLLM-Omni model families.
One nuance matters: not every stage of every pipeline is quantized. VAE decode, auxiliary stages, and parts of multi-stage systems may remain in higher precision. That is why the weight-compression ratio is usually larger than the end-to-end latency speedup.
5.2 Trading Memory Headroom for Latency Reduction
While Section 5.1 established the first-order memory benefit of W4A16, this case study demonstrates how that memory headroom translates into architectural advantages — enabling GPU allocation strategies that deliver real throughput gains beyond what raw compute savings alone would predict. All the aforementioned benchmarks were conducted on Intel XPU B60.
W4A16 Reduces Minimum Hardware from 4 GPUs to only 1 GPU
The BF16 FLUX.1-dev transformer (23 GB) exceeds a single B60’s 24.4 GB capacity once runtime activations are included — it requires TP=4 (all four GPUs) to serve. W4A16’s 7 GB transformer fits comfortably on a single GPU with 19% headroom to spare.
W4A16 + CFG Parallel = 1.55x - 1.67x Faster Guided Generation
Classifier-Free Guidance (CFG) requires running two denoising passes per step — one with the prompt, one with a negative prompt. With BF16 occupying all 4 GPUs for tensor parallelism, these passes must run sequentially (2X latency). W4A16 fits in TP=2, freeing 2 GPUs. This enables CFG Parallel — running both guidance branches simultaneously across two GPU groups:
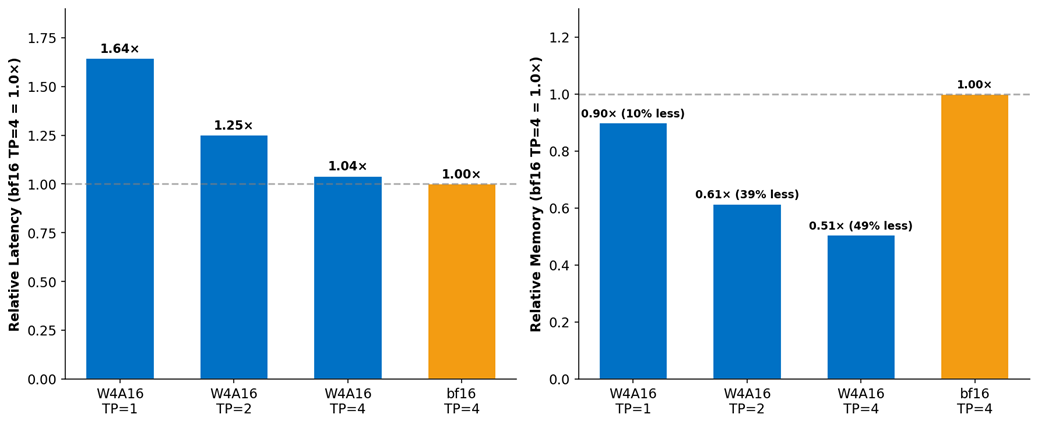
Figure 6: Latency and memory tradeoff analysis: W4A16 reduces minimum hardware requirement from 4 GPUs to 1, enabling CFG Parallel execution.

Figure 7: CFG Parallel execution on Intel XPU B60 achieves 1.55-1.67x speedup over sequential BF16 serving.
The key insight: W4A16’s value in diffusion workloads extends beyond the memory narrative. The memory headroom doesn’t just allow models to fit — it enables them to run differently, unlocking parallelism strategies that produce end-to-end speedups larger than raw dequantization overhead would predict.
6. Conclusion
AutoRound fits vLLM-Omni unusually well because the integration respects what operators actually need: offline checkpoint generation, automatic runtime detection, predictable memory savings, and a path to verify quality before rollout. The result is a practical low-bit serving workflow that now spans a meaningful slice of the vLLM-Omni ecosystem, from FLUX and Wan to GLM, BAGEL, Ovis, and Qwen Omni.
For the broader community, the real takeaway is this: quantization is no longer just a clever trick to win benchmarks — it has matured into foundational infrastructure. As AutoRound broadens its compatibility across model families and hardware architectures, it provides an effective path toward balancing multimodal performance, deployment cost, and output quality.
Ongoing work includes broader format support and continued expansion across model families and hardware targets. We are actively expanding support for additional quantization formats such as MXFP4 and MXFP8 for both Linear and MoE modules, while also exploring low-bit techniques for attention layers (e.g., SageAttention). These improvements will further extend the efficiency and flexibility of multimodal serving in the near future.
7. Acknowledgements
Special thanks to Hongsheng Liu, Shunyang Li, and WeiQing Chen from the vLLM-Omni team, as well as Chendi Xue from Intel, for their incredible support in integrating AutoRound into vLLM-Omni. We are also deeply grateful to the vLLM-Omni community for their rapid adoption of AutoRound!